While writing the code for yesterday's blog post, I ran into a runtime error that I hadn't personally run into before, though it is by no means an uncommon error. The only reason I haven't run into it before is because I haven't before written programs in Java that had significant memory requirements.
Let's look at a section of code from yesterday:
static int size = 2048; static int A[][] = new int[size][size]; static int B[][] = new int[size][size];
Find the complete code here
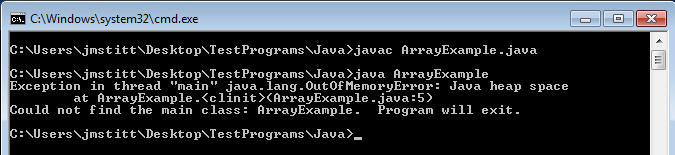
This section is creating and instantiating the int variable "size" then allocating memory for two two-dimensional arrays that contain size2 elements. Let's try adding another 1024 to the size variable and see what happens.
Click for full size
Now that's interesting. The part we're interested in is:
java.lang.OutOfMemoryError: Java heap space at ArrayExample.
Apparently when allocating memory for the second array, we run into a problem, as there is not enough memory. At first glance, this seems strange, as I have 8 gigabytes of ram in this machine, and even though Java can't use all of that because I'm running 32-bit Java, I did not think it would be a problem as the maximum memory still should not have come anywhere near this.
I suppose the question now is how much memory did the example attempt to use? Just looking at the size of the arrays, and not taking into account overhead, the arrays come out to just over 73mb of space. Considering 32-bit allows for ~4gb of space, this still seems odd that we ran into a problem. In order to explain this, we have to focus on another word in the error message:
java.lang.OutOfMemoryError: Java heap space at ArrayExample.
What is the "heap space"?
According to JavaWorld:
The JVM's heap stores all objects created by an executing Java program.
By default, the size of the heap in Java 1.6 is 64mb.
Now we can see that we were, in fact, trying to use more memory than we had available. I have a problem with this though. I want to use more memory than 64mb. Why? Honestly, because I can.
Is this even possible, or are we stuck with this limit?
Luckily for us, Java allows for us to bypass this limit at runtime. By executing the java command with the argument -Xmx and choosing a new maximum heap size, we can set a larger heap size for the program's use.
Example:
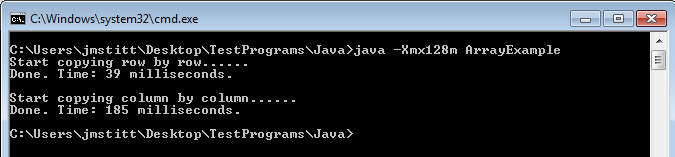
java -Xmx128m ArrayExample
The number in the example is our desired maximum heap size. The "m" after the number designates that we mean megabytes, you can also use "g" for gigabytes, etc.
Let's try it, using the same program as before:
Click for full size
Ah, now it runs correctly, and we can run our test from yesterday with even larger numbers, allowing us to see the difference between the two array copying implementations more clearly. You can go even larger than I did here.
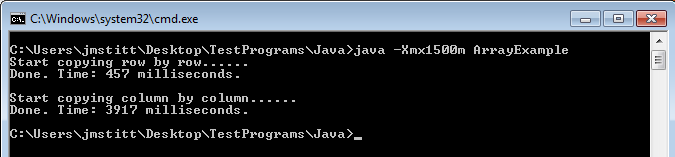
Just as an example, here's a run with arrays containing 102402 (5x as many as yesterday's) elements:
Click for full size
Now we're getting somewhere.
Another problem you may run into is trying to allocate more memory than you have physically in your machine, or just more than allowed. Trying to set the maximum heap to 4g gives an error that it is an invalid maximum heap size. Yet another error you may run into is the JVM not being able to find enough contiguous memory. The heap only allows you to use memory that is in one big block, so just because you have two gigabytes unused on your machine doesn't mean you'll be able to use it (trust me, I tried).
Have some fun with it, see what you can do. I'd love to hear what the maximum size people can get to work on their machines is.
C code still to come, and I'll try to have some other examples besides just this array copying scenario.
Here's some links to more information on the heap and other options:




