Monday night I participated in my first ever programming competition. It was an interesting experience which I thoroughly enjoyed. The competition was held in the Computer Science department, and was open to all students of the University.
The goal of the competition was to find people to go on to the regional competition, which will be either at Murray State University or at Louisiana State University (really want to say something here, but I'll refrain...). The reason for the two locations is that it would depend on what date the team decides to go.
In the competition we were given four problems to solve, and we were told we could access the official documentation for Java, C, and C++ (the three permitted languages), as well as make use of any printed materials we brought with us. Out of the four problems, I was only able to solve one during the competition. Towards the end I sort of stopped trying, since I knew I wouldn't get the others done in time, so I had a little fun with them and tried different things out.
Out of the eight people who competed, I came in sixth, which was fourth out of the people who are eligible to go on to regional. Since a team consists of three people, this leaves me as the first alternate, and I've been told by the coach (who is one of my teachers and a friend), James Church, that I'd go with the team to the competition whether or not I competed myself. I'm all for this.
Considering this was my first time doing a competition, I'm happy with my one correct answer, and with just not coming in last. One thing I learned during the course of the competition, and while looking at Church's solutions afterwards, is that I need to learn a lot more about the classes Java provides for me, as there were a few I didn't know about that would have allowed me to solve another problem or two very easily compared to how I was trying to do things.
This competition is another event that has inspired me to learn more about programming and to improve what I know by practicing. In my free time, I plan on attempting more problem solving exercises like those given in the competition.
Jeff Atwood (@CodingHorror on twitter) retweeted something this morning that was right along these lines. The post was from @enmerinc and said "How to become a better developer: 1) Go to #StackOverflow 2) Pick a question outside of your comfort zone 3) Open your IDE and solve it"
I really liked that idea, and plan on doing that from here on out. I don't know that I'll even average one problem a week, but even so, I'll learn something.
Thursday, September 30, 2010
Wednesday, September 29, 2010
A Desktop Version of a Classic Supercomputer?!?!?!
Normally I'd relegate posts consisting of ranting about something I found on the internet to my tumblr account, but this was too good to post on a blog that no one reads.
*cough*NotThatThisIsMuchBetter*cough*
Excuse me... Anyways, while reading through posts in Google Reader, I saw what may be my favorite thing featured on Hack A Day to date. Since this is coming via Hack A Day, many of you probably saw it already, but for those that haven't I present
A TINY CRAY-1:

That's right, Chris Fenton has created what amounts to a desktop-sized version of this classic supercomputing marvel. It's 1/10 the size of the original, and sports an impressive 33MHz processor (the original only had 80MHz, so no scoffing!). It's not the most useful of devices, but out of all the things I've ever said "I'd love to have one of those on my desk so people would ask what it is," this is probably the coolest.
It will be a while before I undertake this project, if I ever do, but it would definitely be worth it in my opinion. I mean, who hasn't wanted their own personal Cray? I know when I first heard about Cray supercomputers I immediately went to find out how much they cost so I could plan on buying one when I grew up and became rich (still waiting for this).
You can find more pictures, specs, and code (yes, code!) over at Chris Fenton's site. Also, you can check out the Hack A Day article for some discussion in the comments.
*cough*NotThatThisIsMuchBetter*cough*
Excuse me... Anyways, while reading through posts in Google Reader, I saw what may be my favorite thing featured on Hack A Day to date. Since this is coming via Hack A Day, many of you probably saw it already, but for those that haven't I present
A TINY CRAY-1:
That's right, Chris Fenton has created what amounts to a desktop-sized version of this classic supercomputing marvel. It's 1/10 the size of the original, and sports an impressive 33MHz processor (the original only had 80MHz, so no scoffing!). It's not the most useful of devices, but out of all the things I've ever said "I'd love to have one of those on my desk so people would ask what it is," this is probably the coolest.
It will be a while before I undertake this project, if I ever do, but it would definitely be worth it in my opinion. I mean, who hasn't wanted their own personal Cray? I know when I first heard about Cray supercomputers I immediately went to find out how much they cost so I could plan on buying one when I grew up and became rich (still waiting for this).
You can find more pictures, specs, and code (yes, code!) over at Chris Fenton's site. Also, you can check out the Hack A Day article for some discussion in the comments.
Thursday, September 23, 2010
Random Stuff
I've been meaning to write a blog post for the past few days, keep people interested, but it's been a busy week.
So, I told myself, "Self, today is the day, you're writing a blog post."
It's been a long day though, and I've got nothing. So, here's my favorite picture of a wombat:

So, I told myself, "Self, today is the day, you're writing a blog post."
It's been a long day though, and I've got nothing. So, here's my favorite picture of a wombat:
Feel free to share your favorite pictures of wombats in the comments.
P.S. I have a [real] post for tomorrow.
P.P.S. It's Miranda's birthday, so drop her a tweet and check out what she has going on over at Tidbits For Your Wits and Gamespace.
Thursday, September 16, 2010
Password Length and Complexity
I subscribe to quite a few mailing lists, for various topics and reasons. One in particular that catches my attention more often than others is the Security Basics list. This is one of several Security Focus lists that I subscribe to. If you're looking for some lists, this is a good place to start.
One topic in particular that caught my eye today was a question titled simply: "Length vs Complexity." Being a fan of looking at the complexity of things, I decided to see what this was all about.
Responses ranged from people asserting that increasing the length was better than increasing the keyspace (number of possible characters) to other people saying just the opposite.
The main criticism towards longer passwords that were easy to remember (multiple words, instead of random characters) was that it is still subject to dictionary attacks. Granted, it is more difficult to pull off a dictionary attack when it isn't just one word, as you do have to try more possibilities, or possibly have some foreknowledge of the type of password used. People saying this approach was not better were leaning towards saying that a true brute force approach would most likely not be the first thing tried.
Conversely, people saying that the "D*3ft!7z" example was weaker used the argument that it had fewer bits than a longer password with the same keyspace.
I fall in line with the first group. The problem with using bit strength as your metric for password security is that saying a password has a certain amount of bit entropy means you're assuming that each character was randomly generated separate from the other characters. Without making this assumption, you cannot say that a longer password always has more bits of entropy than a shorter one. This is what entropy means.
A few months ago, I wrote a short script in Java to easily do the math on password bit strength. The aforementioned problem is quickly evident when you run the program:
The program could be made more complex. Tests could be added checking to see if all possible types of characters for the given keyspace (numbers and letters; numbers, letters, and special characters; etc.) are actually used. In most cases, this would give a more true value of entropy in the end. Notice I said "in most cases," as this still would not completely solve the problem.
For example, say we have two passwords, "AAAA" and "AFIS" used by two members of Example.com. Example.com only allows users to use capital letters in their passwords, disallowing numbers and special characters. Now, a dictionary attack on these passwords may return no results, but when brute forcing the passwords, it is plainly evident that AAAA is going to be found much faster than AFIS.
Both passwords technically have the same amount of bits, and both passwords technically used all the character types available, but because AFIS was generated randomly, it has more entropy than AAAA.
Testing for randomness is quite a bit more difficult, and I'm not entirely sure you can completely say something is truly random. Though, by doing the best we can, we will, without a doubt, have much stronger passwords.
Nowadays, with the use of GPU's for password cracking, Rainbow Tables, massive botnets, and other forms of computation available to those who would seek to crack people's passwords, it is nearly impossible to say a password really is "secure." All we can hope is that it is "secure enough." The password system is inherently broken, but it will be a long time coming, if it ever does, before we see another system completely replace it that does not suffer from it's own shortcomings.
You can find the thread from the mailing list here.
One topic in particular that caught my eye today was a question titled simply: "Length vs Complexity." Being a fan of looking at the complexity of things, I decided to see what this was all about.
Users hear constantly that they should add complexity to their passwords, but from the math of it doesn't length beat complexity (assuming they don't just choose a long word)? This is not to suggest they should not use special characters, but simply that something like Security.Basics.List would provide better security than D*3ft!7z. Is that correct?
Responses ranged from people asserting that increasing the length was better than increasing the keyspace (number of possible characters) to other people saying just the opposite.
The main criticism towards longer passwords that were easy to remember (multiple words, instead of random characters) was that it is still subject to dictionary attacks. Granted, it is more difficult to pull off a dictionary attack when it isn't just one word, as you do have to try more possibilities, or possibly have some foreknowledge of the type of password used. People saying this approach was not better were leaning towards saying that a true brute force approach would most likely not be the first thing tried.
Conversely, people saying that the "D*3ft!7z" example was weaker used the argument that it had fewer bits than a longer password with the same keyspace.
I fall in line with the first group. The problem with using bit strength as your metric for password security is that saying a password has a certain amount of bit entropy means you're assuming that each character was randomly generated separate from the other characters. Without making this assumption, you cannot say that a longer password always has more bits of entropy than a shorter one. This is what entropy means.
A few months ago, I wrote a short script in Java to easily do the math on password bit strength. The aforementioned problem is quickly evident when you run the program:
The program could be made more complex. Tests could be added checking to see if all possible types of characters for the given keyspace (numbers and letters; numbers, letters, and special characters; etc.) are actually used. In most cases, this would give a more true value of entropy in the end. Notice I said "in most cases," as this still would not completely solve the problem.
For example, say we have two passwords, "AAAA" and "AFIS" used by two members of Example.com. Example.com only allows users to use capital letters in their passwords, disallowing numbers and special characters. Now, a dictionary attack on these passwords may return no results, but when brute forcing the passwords, it is plainly evident that AAAA is going to be found much faster than AFIS.
Both passwords technically have the same amount of bits, and both passwords technically used all the character types available, but because AFIS was generated randomly, it has more entropy than AAAA.
Testing for randomness is quite a bit more difficult, and I'm not entirely sure you can completely say something is truly random. Though, by doing the best we can, we will, without a doubt, have much stronger passwords.
Nowadays, with the use of GPU's for password cracking, Rainbow Tables, massive botnets, and other forms of computation available to those who would seek to crack people's passwords, it is nearly impossible to say a password really is "secure." All we can hope is that it is "secure enough." The password system is inherently broken, but it will be a long time coming, if it ever does, before we see another system completely replace it that does not suffer from it's own shortcomings.
You can find the thread from the mailing list here.
ShoeCon Reminder
This Saturday, the 18th, is the date of ShoeCon 2010, in Atlanta. I'd love to make it, but will not be able to due to having family in town. If any of you will be in the Atlanta area, you really should try to go. The event is a conference being held to celebrate the life of Matthew Shoemaker, a friend to many in the InfoSec community. Any proceeds from the conference go in a fund to help care for Matthew's children. Please keep his family in your thoughts and prayers.
More on ShoeCon over at ShoeCon.org.
More on ShoeCon over at ShoeCon.org.
Wednesday, September 15, 2010
Day Off From Social Media
One thing I've heard many times the past couple of years is that people are much more connected than they have ever been before. We have cell phones, text messaging, e-mail, instant messaging, Twitter, Facebook, etc. The list of ways we're constantly connected to other people is nearly endless, and new services pop up all the time to make this connectivity even easier. Having a smart phone means you are rarely without the internet at your fingertips, meaning you have access to all this connectivity more often than just a few years ago, when smartphones were rarities. With these services, it is amazing how much communication a person can manage in a day!
I can't find a link right now, but I remember seeing a study showing that the number of people we can actively keep in our mental social circle is fairly small, less than 200 if I remember correctly. The study showed that the use of Facebook and other social sites these days has actually lead to an increase in this number. This is amazing, as with around 600 people connected to me on Facebook, and another 200 or so on Twitter, as well as elsewhere, it would be nearly impossible to keep track of this many people without these services. Granted, not all of those people are very active, and I don't keep track of all of them to much extent, but the fact that I could if I chose to is dumbfounding.
Something else I hear said these days is that people may be suffering from what can be called "information overload" due to all of this connectivity. I can understand this, as there are plenty of days where I feel I just can't keep up with everything that is going on around me and in my online social circle. The amount of information is staggering, especially on Twitter, where I attempt to read everything posted by those I'm following.
Lately I've begun playing Empire Avenue, which has been both a blessing and a curse. It has connected me to so many more people that I otherwise probably would not have found, increasing readership of this personal blog, as well as gaining quite a few new followers for me on Twitter. I've even signed up for Flickr as a result of joining the site, so now I'm becoming active in a small photography community. All of that is very good, and I enjoy it. The problem is that due to all of this social growth, the amount of information and contact I receive every day has gone up dramatically, and those days I feel I can't keep up with everyone have happened more often.
Yesterday, I decided I was going to just take the day off. I don't have a job, other than being a full time student, so social media feels like a part-time job to me sometimes. I felt that I needed a day off. A few people contacted me when I didn't post my usual round of "good mornings" around the web, asking if I had actually gotten out of bed, but for the most part, I didn't have very many people contact me.
The peace and quiet of the day was refreshing. The last time I spent any length taking a break from the internet was when I spent a week in Costa Rica on a mission trip. Having been online for a good chunk of my life, leaving the internet is an interesting feeling for me, as the day feels as if it slows down when I'm disconnected. I spent a good deal of time yesterday reading and writing, things I haven't been doing as much over the past few months. Time was spent sitting and thinking, something I don't remember doing in quite some time.
In all, I enjoyed my day off, and plan on having more in the future. If it's been a while since the last time you "disconnected," then I suggest you give it a try. Who knows, you might find that you like it.
I can't find a link right now, but I remember seeing a study showing that the number of people we can actively keep in our mental social circle is fairly small, less than 200 if I remember correctly. The study showed that the use of Facebook and other social sites these days has actually lead to an increase in this number. This is amazing, as with around 600 people connected to me on Facebook, and another 200 or so on Twitter, as well as elsewhere, it would be nearly impossible to keep track of this many people without these services. Granted, not all of those people are very active, and I don't keep track of all of them to much extent, but the fact that I could if I chose to is dumbfounding.
Something else I hear said these days is that people may be suffering from what can be called "information overload" due to all of this connectivity. I can understand this, as there are plenty of days where I feel I just can't keep up with everything that is going on around me and in my online social circle. The amount of information is staggering, especially on Twitter, where I attempt to read everything posted by those I'm following.
Lately I've begun playing Empire Avenue, which has been both a blessing and a curse. It has connected me to so many more people that I otherwise probably would not have found, increasing readership of this personal blog, as well as gaining quite a few new followers for me on Twitter. I've even signed up for Flickr as a result of joining the site, so now I'm becoming active in a small photography community. All of that is very good, and I enjoy it. The problem is that due to all of this social growth, the amount of information and contact I receive every day has gone up dramatically, and those days I feel I can't keep up with everyone have happened more often.
Yesterday, I decided I was going to just take the day off. I don't have a job, other than being a full time student, so social media feels like a part-time job to me sometimes. I felt that I needed a day off. A few people contacted me when I didn't post my usual round of "good mornings" around the web, asking if I had actually gotten out of bed, but for the most part, I didn't have very many people contact me.
The peace and quiet of the day was refreshing. The last time I spent any length taking a break from the internet was when I spent a week in Costa Rica on a mission trip. Having been online for a good chunk of my life, leaving the internet is an interesting feeling for me, as the day feels as if it slows down when I'm disconnected. I spent a good deal of time yesterday reading and writing, things I haven't been doing as much over the past few months. Time was spent sitting and thinking, something I don't remember doing in quite some time.
In all, I enjoyed my day off, and plan on having more in the future. If it's been a while since the last time you "disconnected," then I suggest you give it a try. Who knows, you might find that you like it.
Sunday, September 5, 2010
Code Complexity Classes II: Revisited
Here's that C code I've been promising:
Compiled in 64-bit Ubuntu 10.4.
When you run the code, just as in Java, you can see the difference in time between the "row by row" and "column by column" implementations:
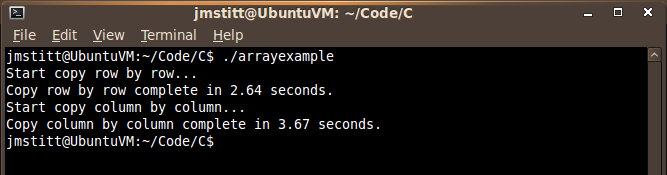
The row by row implementation ran in 2.64 seconds according to the timer built into the program, with the column by column example running in 3.67 seconds.
This is in a VM, so comparisons to the Java example done before should not be made, as those examples were tested in the host OS. As always with things like this, the time is subject to your unique system and what is running at the time of execution.
What is important though, is to notice the difference in time between the two implementations, it is still there, and it is a noticeable amount, even with this relatively small amount of data.
Just for curiosity's sake, I decided to see how turning optimization flags on would affect the execution time:
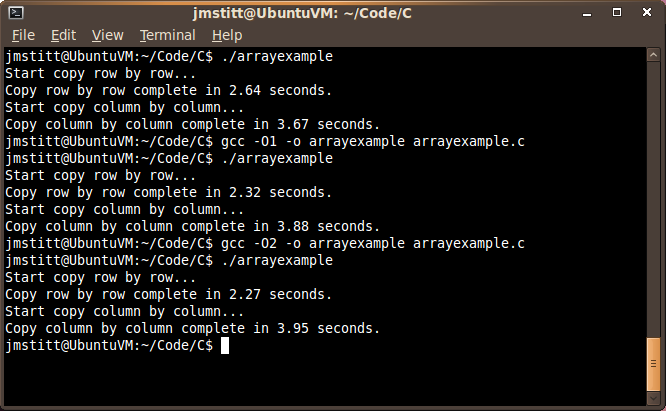
With first level optimization, our row by row time dropped considerably to 2.32 seconds, and our column by column implementation time went up to 3.88 seconds, further increasing the gap.
With second level optimization, row by row dropped again to 2.27, and column by column further increased to 3.95. As you can see, this time the change was negligible.
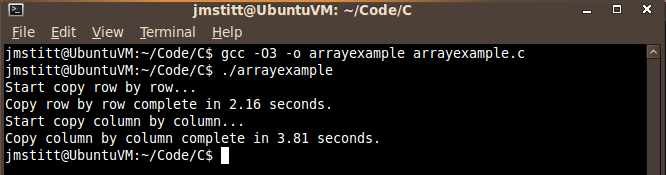
With third level optimization, we saw a decrease about half that of first level optimization in the time for row by row copying to 2.16. This optimization also decreased the column by column time to below that of first level optimization, but higher than that of no optimization, putting it at 3.81 seconds.
I'm not going to go into what exactly these optimization flags do, as that's a topic for another post, and I'm not even sure what all is done myself at this point. I'm extremely new to C, so if you see anything incorrect in this post, feel free to point out my mistakes, and I'll be happy to correct them and give credit where credit is due.
Speaking of where credit is due, I must give some to my Assembly Language teacher, Dr. Chen, for providing the basic version of this code (I only added the timer and made some minor tweaks to suit my cosmetic style) and for providing the inspiration for these posts on complexity classes and how they stack up in the real world. Perhaps in the future I'll revisit this topic more in depth, for now though, I am done with it.
Compiled in 64-bit Ubuntu 10.4.
When you run the code, just as in Java, you can see the difference in time between the "row by row" and "column by column" implementations:

The row by row implementation ran in 2.64 seconds according to the timer built into the program, with the column by column example running in 3.67 seconds.
This is in a VM, so comparisons to the Java example done before should not be made, as those examples were tested in the host OS. As always with things like this, the time is subject to your unique system and what is running at the time of execution.
What is important though, is to notice the difference in time between the two implementations, it is still there, and it is a noticeable amount, even with this relatively small amount of data.
Just for curiosity's sake, I decided to see how turning optimization flags on would affect the execution time:
With first level optimization, our row by row time dropped considerably to 2.32 seconds, and our column by column implementation time went up to 3.88 seconds, further increasing the gap.
With second level optimization, row by row dropped again to 2.27, and column by column further increased to 3.95. As you can see, this time the change was negligible.

With third level optimization, we saw a decrease about half that of first level optimization in the time for row by row copying to 2.16. This optimization also decreased the column by column time to below that of first level optimization, but higher than that of no optimization, putting it at 3.81 seconds.
I'm not going to go into what exactly these optimization flags do, as that's a topic for another post, and I'm not even sure what all is done myself at this point. I'm extremely new to C, so if you see anything incorrect in this post, feel free to point out my mistakes, and I'll be happy to correct them and give credit where credit is due.
Speaking of where credit is due, I must give some to my Assembly Language teacher, Dr. Chen, for providing the basic version of this code (I only added the timer and made some minor tweaks to suit my cosmetic style) and for providing the inspiration for these posts on complexity classes and how they stack up in the real world. Perhaps in the future I'll revisit this topic more in depth, for now though, I am done with it.
Subscribe to:
Posts (Atom)